
Cuando desarrollamos una funcionalidad, una vez tenemos claro qué es lo que hay que hacer, empezamos a escribir el código que vaya implementando la solución. Muchas veces esto genera un código que, aunque funciona, no es entendible en la actualidad ni mucho menos en el futuro (cuando haya que mantenerlo).
En este post daremos a conocer los fundamentos del código limpio e indicaremos pautas a seguir para que nuestro código sea lo más limpio posible, desde lo más básico a lo más complejo. Para ello nos basaremos en el libro “Clean Code: A Handbook of Agile Software Craftsmanship”, de Robert C. Martin.
Las cosas claras desde el inicio
Decimos que un código es limpio si:
- Es simple y directo. No debe esconder intenciones; si hace falta incluir un comentario probablemente no deba considerarse limpio.
- Es específico y no especulativo.
- Contiene pruebas.
- Está redactado de forma legible.
Debemos mantener el código lo más limpio posible. Recomendamos seguir, con este propósito, la regla del Boy Scout: intenta entregar el código más limpio de lo que lo encontraste. Es decir, si ves que es necesario dividir una función demasiado extensa, realizar un cambio de nombre, eliminar un duplicado o simplificar una instrucción, no dudes en hacerlo ya que mejorarás el código.
Nombres
A tener en cuenta:
- Nombres con sentido. El nombre debe indicar para qué existe, qué hace y cómo se usa. Por ejemplo,
int d; //tiempo transcurrido en díasdebería serint elapsedTimeInDays; - Diferencia nombres. Si los nombres solo se diferencian en una letra, es difícil distinguirlos.
- Evita la desinformación. Rehuye usar palabras que se alejen del sentido/intención del código y cometer errores ortográficos( por regla general los elementos serán mostrados en orden alfabético).
- Distinciones con sentido y evitar codificación. Debe ser entendido por cualquier persona que lo lea.
- Nombres pronunciables y fáciles de encontrar. Evita usar prefijos o sufijos y/o asignaciones mentales.
- Nombres de clases y objetos. Usa nombres o frases, nunca verbos, ya que se utilizan para nombrar métodos.
- Nombres de métodos. Deben ser verbos. Usa el prefijo (
get,set,is). - Dominios de soluciones. Emplea términos informáticos, algoritmos, nombres de patrones, términos matemáticos, etc. Ejemplos:
AccountVisitor,UserSingleton. - Dominios de problemas. Utiliza un término del dominio del problema. Ejemplos:
ParkingSpot,IncidenceUser.
Funciones
Son la primera línea organizativa en cualquier programa. Estas deben:
- Ser de tamaño reducido.
- Tener un nivel de sangrado de uno o dos para que sean más fáciles de leer y entender.
- Hacer una sola cosa y hacerla bien (no se pueden dividir en secciones). Para saber si una función solo realiza una cosa, esta debe realizar los pasos situados un nivel por debajo del nombre de la función.
- Las instrucciones de la función deben encontrarse en el mismo nivel de abstracción; la mezcla de niveles resultará confusa.
- Cuanto más reducida y concreta sea una función más sencillo será asignarle un nombre descriptivo y simple, aunque no hay por qué tenerle miedo a los nombres extensos si son necesarios.
Código de la función
El objetivo es poder leer el código como un texto, de arriba a abajo, lo que se llama regla descendente.
En lo que respecta a las instrucciones switch, cuando nos sea imposible evitarlas, debemos asegurarnos de incluirlas en una clase de nivel inferior y de no repetirlas.
- Argumentos de funciones. El número ideal es cero (máximo dos). Evita transformar el objeto de entrada. Si se hace, la función debe devolver el objeto recibido como parámetro de entrada. Evita pasar un boolean como parámetro de entrada. Las funciones condicionales (hacen una cosa si la entrada es
truey otra si la entrada esfalse) son confusas - Argumentos como objetos. Cuando una función parece necesitar dos o más argumentos, es posible que algunos se puedan agrupar en una clase propia.
Circle makeCircle(double x, double y, double radius)se convierte enCircle makeCircle(Point center, double radius). - Evita usar argumentos de salida. Es mejor crear un método en el objeto que se quiere modificar.
- Rehuye usar una función para hacer algo y responder a algo a la vez.
if (set(“username”, “usuario”))...¿Qué hace? ¿El atributo username se ha establecido con el valor usuario? Mejor separar el método set en 2:if (attributeExists(“username”)) { setAttribute(“username”, “usuario”); }
- Uso de excepciones. Es mejor usar excepciones que usar códigos de error.Es mejor separar en una función los bloques try/catch:
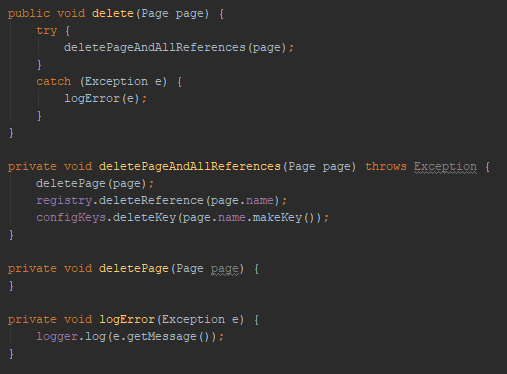
Programación estructurada
Una función de gran tamaño debe tener una entrada y una salida, ya que facilita seguir el flujo del algoritmo, por lo que solo debe tener un return, no debe haber break o continue y nunca se debe usar la instrucción goto.
En este sentido se recomienda crear funciones que sean claras, concisas, pequeñas, que hagan una sola cosa. No obstante, con el mínimo de argumentos es prácticamente imposible hacerlo a la primera. Por eso, una vez escrito el código, es necesario retocarlo: dividir las funciones, cambiar los nombres y eliminar los duplicados, reducir los métodos y reordenarlos, incluso eliminar clases enteras. Al final, se obtienen funciones que cumplen las reglas indicadas, obteniendo un código más limpio.
Comentarios
Antes de escribir un comentario hay que pensar si existe otra forma de expresarse en el código. Dado que el código cambia y evoluciona, debería aplicarse la disciplina como de mantener los comentarios actualizados, relevantes y precisos.
Solo se deben incluir comentarios en las ocasiones en las que sean realmente necesarios. Sin embargo, siempre es preferible emplear ese tiempo en crear un código claro y expresivo.
Cuando haya que añadir un comentario, hay que asegurarse que este describa el código que lo rodea. De igual modo, hay que garantizar que los comentarios son de calidad, estrictamente necesarios o beneficiosos, informativos, aclaratorios, de advertencia y/o de amplificación para determinar la importancia de algo que a simple vista puede parecer insignificante.
Es preferible explicar nuestra intención en el código antes que recurrir a un comentario. En ocasiones se puede crear una función o una variable que diga lo mismo que el comentario.
Otras recomendaciones:
- Evitar poner comentarios
TODO. Examina tu código y elimínalo, ya que solo harán que el código sea incorrecto y falle. - No incluyas reflexiones históricas ni descripciones de detalles irrelevantes.
- No es necesario tener comentarios obligatorios ni periódicos que indiquen los cambios al inicio de cada módulo, para eso existe el sistema de control de código fuente.
- Evita incluir comentarios HTML ya que solo dificultan la lectura.
Formato
El formato debe ser claro y las reglas establecidas deben seguirse en su totalidad. La legibilidad del código afectará a todos los cambios que se realicen a posteriori.
Formato vertical
- Los ficheros de pocas líneas de código son más fáciles de entender. El tamaño aconsejado es de 500 líneas como máximo.
- Las líneas en blanco se usan para separar conceptos independientes.
- La densidad vertical establece relaciones entre las líneas de código:
public class ReporterConfig {
private String mClassName;
private List mProperties = new ArrayList();
public void addProperty(Property property) {
mProperties.add(property);
}
}
- Queda claro que es una clase con dos atributos y un método, frente a esta misma clase con comentarios:
public class ReporterConfig { /** * Nombre de clase del escuchador */ private String mClassName; /** * Propiedades del escuchador */ private ListmProperties = new ArraryList (); public void addProperty(Property property) { mProperties.add(property); } } - Los conceptos relacionados entre sí deben mantenerse juntos verticalmente. Para que un código sea legible hay que evitar estar navegando entre archivos y clases.
- Declaración de variables:
- Las variables locales deben declararse al principio de cada función.
- Las variables de control de bucles deben declararse en la instrucción del bucle.
- Los atributos de una clase deben declararse al principio de la clase y no intercalar sus declaraciones entre los métodos.
- Funciones dependientes:
- Si una función invoca a otra, deben estar verticalmente próximas y, siempre que sea posible, la función invocadora debe estar por encima de la invocada. Esto facilita la lectura del código. Al principio del código deben aparecer los conceptos más importantes y, al ir bajando, deben aparecer los detalles cada vez menos importantes.
- Funciones que realicen tareas parecidas deben aparecer próximas en el código.
Formato horizontal
- Máximo de caracteres en una línea: los suficientes como para no tener que desplazar la lectura hacia la derecha.
- Utilizar espacios en blanco para separar elementos. Por ejemplo,
int lineSize=line.length, quedan separadas la parte izquierda y la parte derecha de la asignación.
Sangrado
El sangrado sirve para visibilizar la jerarquía de ámbitos:
- Nivel 0: clases
- Nivel 1: métodos
- Nivel 2: implementación de método
- Nivel 3 y sucesivos: implementación de bloques
Lo importante es definir las reglas que el equipo va a usar y usarlas durante todo el ciclo de vida del software.
Objetos y estructuras de datos
Los objetos ocultan sus datos detrás de abstracciones y muestran funciones que operan con dichos datos. Además, facilitan la inclusión de nuevas clases sin cambiar las funciones existentes.
Ejemplo:

Las estructuras de datos muestran sus datos pero no tienen funciones con significado. Facilitan la inclusión de nuevas funciones sin modificar las estructuras de datos existentes.
Ejemplo:
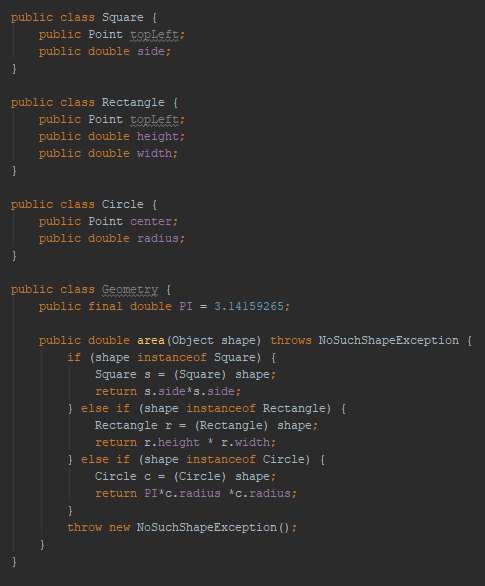
En la medida de lo posible, evita añadir get y set de todo, ya que se expone el estado de los objetos.
Lo importante es que en las partes de un sistema donde se necesiten usar nuevos tipos de datos, se usen objetos y, en las partes en las que se quiera añadir nueva funcionalidad, es mejor usar estructuras de datos y procedimientos.
Procesar errores
Controlar los errores es necesario para que el código haga lo que tiene que hacer en situaciones en las que las entradas sean incorrectas o los dispositivos fallen.
Cuando se usen excepciones, en vez de códigos de error, es necesario incluir mensajes de error con las excepciones que permitan saber cuál es el motivo de la excepción. Con esto, se facilita el registro del error y su posterior tratamiento.
Es recomendable envolver un API de terceros para encapsular distintas excepciones en una sola, dejando un código mucho más limpio.
Por ejemplo:
ACMEPort port = new ACMEPort(12);
try {
port.open();
} catch (DeviceResponseException e) {
reportPortError(e);
logger.log("Device response exception", e);
} catch (ATM1212UnlockedException e) {
reportPortError(e);
logger.log("Unlock exception", e);
} catch (GMXError e) {
reportPortError(e);
logger.log("Device response exception", e);
} finally {
...
}
Se puede convertir en:
LocalPort port = new LocalPort(12);
try {
port.open();
} catch (PortDeviceFailure e) {
reportError(e);
logger.log(e.getMessage(), e);
} finally {
...
}
public class LocalPort {
private ACMEPort innerPort;
public LocalPort (int portNumber) {
innerPort = new ACMEPort(portNumber);
}
public void open() {
try {
innerPort.open();
} catch (DeviceResponseException e) {
throw new PortDeviceFailure(e);
} catch (ATM1212UnlockedException e) {
throw new PortDeviceFailure(e);
} catch (GMXError e) {
throw new PortDeviceFailure(e);
}
}
...
Al separar la lógica de negocio del control de errores, la detección de errores se desplaza a los bordes del programa.
Hay que evitar devolver null. Al hacerlo hay que estar comprobando constantemente que un resultado es distinto de null. Solo es necesario que no se compruebe una vez para que se genere un NullPointerException y la ejecución falle. En vez de eso, lo recomendable es devolver una excepción o devolver un objeto de caso especial.
Tampoco se debe pasar null como parámetro de entrada, ya que pueden generar NullPointerException. Para solucionarlo:
- Comprobar en la función que, si el parámetro es nulo, se lance una excepción. Con esto hay que capturar esa excepción posteriormente.
- En la función, añadir
assert. ¡Ojo! Esto no impide que se produzca un error en tiempo de ejecución. - Diseñar el código para que
nullnunca sea un posible valor de entrada de los métodos. De esta forma, se minimiza el número de errores.
Lo importante es separar el control de errores del resto de lógica principal. Así, el mantenimiento del código será más sencillo.
Límites
En el software que desarrollamos, normalmente hay librerías de terceros que no controlamos y que debemos integrar con nuestro código.
El código de terceros suele ser muy flexible y ofrece más funcionalidad de la necesaria. Por ejemplo, podemos querer usar un Map pero que este no permita borrar elementos. Si devolvemos el Map directamente, cualquiera puede llamar al método clear y borrar todos los elementos. Para solucionarlo, creamos una clase que utilice el Map pero que exponga los métodos que realmente queremos que sean usados.
Por ejemplo:
public class Sensors {
private Map sensors = new HashMap();
public Sensor getById(String id) {
return (Sensor) sensors.get(id);
}
...
}
No hay que encapsular todos los usos de Map, sino impedir que se use Map por el resto del sistema. De esta forma se genera código más fácil de entender y con menor probabilidad de errores. Si se usa una interfaz como Map, lo mejor es mantenerla dentro de la clase o conjunto de clases en las que se use y evitar devolverla o recibirla como parámetro en una API pública.
En los límites entre lo conocido y lo desconocido se encuentran los problemas. Lo mejor que podemos hacer es crear una interfaz y pruebas que se adapten a lo que necesitamos y posteriormente crear la integración con la librería de terceros. De esta forma, cuando cambie el código de terceros, el mantenimiento será menor.
Pruebas unitarias
Las tres leyes del TDD (Test Driven Development):
- Primera ley. No debe crear código de producción hasta que no haya creado una prueba unitaria que falle.
- Segunda ley. No debe crear más de una prueba unitaria que dé fallo y no compilar se considera fallo.
- Tercera ley. No debe crear más código de producción que el necesario para superar la prueba de fallo actual.
Siguiendo estas tres leyes, las pruebas construidas contemplarán todos los aspectos de nuestro código. También hay que tener en cuenta que el código de prueba es tan importante como el de producción.
Para que una prueba sea limpia, debe ser legible. Por tanto, deben ser claras, simples y agrupar significados. Una prueba debe decir mucho con el menor número de expresiones posible. Para ello hay que seguir el patrón Generar-Operar-Comprobar. Este patrón divide el test en tres partes:
- En una primera parte, se crean los datos de prueba.
- En una segunda parte, se opera con dichos datos, se llama al método que se quiere probar.
- En una tercera parte, se comprueba que los datos obtenidos coinciden con los datos esperados.
Las pruebas limpias siguen estas cinco reglas, cuyas iniciales forman las siglas FIRST en inglés:
- Rapidez. Las pruebas deben ser rápidas y ejecutarse de forma rápida. Si tardan mucho, no se ejecutarán con frecuencia y por tanto no se detectarán los problemas con suficiente antelación.
- Independencia. Las pruebas deben ser independientes entre ellas, no deben condicionar a las siguientes pruebas, ya que si una falla, provocará una sucesión de fallos que dificultará el análisis del error.
- Repetición. Las pruebas se tienen que poder repetir en cualquier entorno.
- Validación automática. Las pruebas o aciertan o fallan, no hay que estar leyendo un texto que indique los resultados o comparar dos archivos.
- Puntualidad. Las pruebas deben crearse antes que el código de producción que hace que acierten. Si se hace al revés, probar el código puede resultar difícil.
Clases
Una clase debe dividirse en dos bloques:
- Un primer bloque de variables. Este, a su vez, se divide en:
- Constantes estáticas públicas
- Variables estáticas privadas
- Atributos privados
- Un segundo bloque de métodos. Después de cada función pública se incluyen las funciones invocadas por la función pública, cumpliendo así la regla descendente.
Las clases deben tener un tamaño reducido: mientras que en las funciones se contaba el número de líneas, el tamaño de las clases se mide en responsabilidades.
De aquí surge el Principio de Responsabilidad Única (SRP), que indica que una clase o módulo debe tener uno y solo un motivo para cambiar, es decir una responsabilidad.
Si el sistema es grande y complejo, siempre va a ser mejor tener muchas clases que hagan una sola cosa a tener pocas clases que hagan muchas cosas. Cualquier cambio a realizar será más fácil de encontrar.
Sistemas
En el desarrollo de un sistema, es importante separar el proceso de inicio, donde se crean los objetos y se conectan las dependencias, de la lógica de ejecución que se realiza tras la inicialización de objetos.
La programación orientada a aspectos (AOP) consiste en asignar responsabilidades de forma transversal a la aplicación. Aspectos transversales como la persistencia, la seguridad, las transacciones o el almacenamiento en caché, se separan del resto de lógica de negocio para mantener un código más limpio. Cada objeto es envuelto por un aspecto que , a su vez, es envuelto por otro objeto que, a su vez, es envuelto por aspecto, formando una especie de muñeca rusa en la que en cada nivel se amplía el comportamiento del objeto. Por ejemplo, en Spring, cuando se llama a un objeto cuya clase está anotada con @Service, no se está llamando realmente al objeto, sino que se llama a un proxy que puede añadir transaccionalidad definida transversalmente en la aplicación sin que el uso del objeto se vea alterado.
Este código generado es más limpio y fácil de mantener, ya que se añade funcionalidad a nivel global sin alterar (no mucho) las clases definidas.
En resumen, los sistemas también deben ser limpios. Deben tener una arquitectura lo menos invasiva posible, afectando la calidad en lo mínimo. Para conseguir que los objetivos sean claros en todos los niveles de abstracción, se han de usar aspectos para añadir funcionalidad transversal sin modificar la implementación ya realizada.
Reglas del código limpio
Se considera que un diseño es sencillo y de calidad si cumple las siguientes cuatro reglas:
- Ejecuta todas las pruebas. Si diseñamos un sistema que se puede probar por completo, es un sistema que se puede comprobar que funciona de la forma esperada. Para que todo se pueda probar, las clases deben ser de tamaño pequeño, que cumplan el principio de responsabilidad única. Si además usamos la inyección de dependencias y realizamos las comunicaciones mediante interfaces, obtenemos un código poco acoplado.
- No contiene duplicados. Es importante eliminar código duplicado porque supone un esfuerzo adicional para mantenerlo. Eliminar código duplicado se puede hacer de varias maneras:
- Invocar métodos que implementen la lógica que necesitamos. Por ejemplo:
boolean isEmpty() { return 0 == size(); } - Extraer secuencias de código repetido en varios métodos.
- Extraer un método a una clase para que pueda ser reutilizado por otras clases.
- Si dos clases comparten lógica, crear una clase padre que contenga la lógica común y que las hijas implementen sólo la parte específica.
- Invocar métodos que implementen la lógica que necesitamos. Por ejemplo:
- Expresa la intención del programador. Cuanto más claro sea el código, menos tiempo tendrán que invertir otros desarrolladores en entenderlo. Con esto, se reducen defectos y el coste del mantenimiento.
- Si los nombres de las clases y de las funciones son adecuados, sus responsabilidades estarán claras. Usar nombres de patrones en los nombres de las clases indica lo que van a hacer esas clases.
- Si las funciones y las clases son pequeñas, son más fáciles de comprender. Si las pruebas están bien escritas, se facilita el entendimiento de una clase.
- Minimiza el número de clases y métodos. Al refactorizar código y extraer la funcionalidad a otros métodos y clases, se puede llegar a tener un número alto de clases y métodos pequeños. El objetivo es reducir el tamaño del sistema teniendo menos clases y métodos. Sin embargo, aunque es importante mantener un número reducido de clases y métodos, más importante es cumplir el resto de reglas.
En conclusión, crear un código limpio permite crear software de calidad, fácil de mantener, entendible por los demás y abierto a añadir nuevas funcionalidades con coste mínimo.

Pedro Caro
Web Technical Lead








